Kafka集群搭建
一、软件环境
Linux: CentOS_7_5_64_org
JDK: jdk1.8.0_172
Zookeeper : zookeeper-3.5.4-beta
Kafka:kafka_2.11-1.1.0
三台Linux服务器:
192.168.3.161
192.168.3.162
192.168.3.163
二、Zookeeper集群搭建
首先,要搭建Zookeeper集群,因为Kafka集群是把状态保存在Zookeeper中的。
Linux服务器,数量最好奇数,也可以用偶数:Zookeeper集群的工作是超过半数才能对外提供服务,3台中允许1台挂掉。
如果有四台那么挂掉一台还剩下三台服务器,可以正常提供服务;在挂掉一个就不能对外提供服务,挂掉的机器不能超过半数。
准备工作
三台服务器的操作相同。
1、安装Java环境 2、定义好目录结构,防止在项目过多的时候找不到所需的项目
1
2
3
4
5
6
7
#目录统一放在/usr下面
#首先创建Zookeeper项目目录
mkdir zookeeper #项目目录
mkdir zkdata #存放快照日志
mkdir zkdatalog #存放事物日志
#解压软件
tar -zxvf zookeeper-3.5.4.tar.gz
修改配置文件
进入到解压好的目录里面的conf目录中,查看文件
1
2
3
4
5
6
7
#进入conf目录
cd /usr/zookeeper/zookeeper/zookeeper-3.5.4-beta/conf
---
#查看
configuration.xsl
log4j.properties
zoo_sample.cfg #主要是这个配置文件
zoo_sample.cfg 这个文件是官方给的zookeeper的样板文件,复制一份命名为zoo.cfg。zoo.cfg是官方指定的文件命名规则。
配置zoo.cfg 注意:修改zookeeper默认端口,不要与kafka自带zookeeper端口冲突。
1
2
3
4
5
6
7
8
9
10
11
tickTime=2000
initLimit=10
syncLimit=5
dataDir= /usr/zookeeper/zkdata
dataLogDir= /usr/zookeeper/zkdatalog
clientPort=12181
server.1=192.168.3.161:12888:13888
server.2=192.168.3.162:12888:13888
server.3=192.168.7.163:12888:13888
#server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里
#192.168.3.161为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口,默认是3888
配置文件解释:
- tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
- initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒。
- syncLimit:这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是5*2000=10秒。
- dataDir:快照日志的存储路径。
- dataLogDir:事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir指定的目录,这样会严重影响zookeeper的性能,当zookeeper吞吐量较大的时候,产生的事物日志、快照日志太多。
- clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求,默认是2181。
创建myid文件
服务器1的配置
1
echo "1" > /usr/zookeeper/zkdata/myid
服务器2的配置
1
echo "2" > /usr/zookeeper/zkdata/myid
服务器3的配置
1
echo "3" > /usr/zookeeper/zkdata/myid
重要配置说明
myid文件和server.myid在快照目录下存放的标识本台服务器的文件,他是整个zookeeper集群用来发现彼此的一个重要标识。zoo.cfg文件是zookeeper配置文件,在conf目录里。log4j.properties文件是zookeeper的日志输出文件,在conf目录里,用java写的程序基本上有个共同点,日志都用log4j来进行管理。zkEnv.sh和zkServer.sh文件zkServer.sh主的管理程序文件zkEnv.sh是主要配置,zookeeper集群启动时配置环境变量的文件
- 当使用默认配置时,zookeeper服务器不会删除旧的快照和日志文件,这是操作人员的职责。
删除快照和日志方法
第一种:可以通过命令去定期的清理。
1
2
3
4
5
6
7
8
9
10
11
12
#!/bin/bash
#snapshot file dir
dataDir=/usr/zookeeper/zkdata/version-2
#tran log dir
dataLogDir=/usr/zookeeper/zkdatalog/version-2
#Leave 66 files
count=66
count=$[$count+1]
ls -t $dataLogDir/log.* | tail -n +$count | xargs rm -f
ls -t $dataDir/snapshot.* | tail -n +$count | xargs rm -f
注:以上这个脚本定义了删除对应两个目录中的文件,保留最新的66个文件,可以将他写到crontab中,设置为每天凌晨2点执行一次就可以了。
第二种:使用zookeeper的工具类PurgeTxnLog,它的实现了一种简单的历史文件清理策略,可以在这里看一下它的使用方法 。
http://zookeeper.apache.org/doc/r3.4.6/zookeeperAdmin.html
第三种:对于上面这个执行,zookeeper自己已经写好了脚本,在bin/zkCleanup.sh中,所以直接使用这个脚本也是可以执行清理工作的。
第四种:从3.4.0开始,zookeeper提供了自动清理snapshot和事务日志的功能,通过配置 autopurge.snapRetainCount 和 autopurge.purgeInterval 这两个参数能够实现定时清理了。这两个参数都是在zoo.cfg中配置的。
- autopurge.purgeInterval: 参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
- autopurge.snapRetainCount :上面的参数搭配使用,指定了需要保留的文件数目,默认是保留3个。
推荐使用第一种方法,对于运维人员来说,将日志清理工作独立出来,便于统一管理也更可控。毕竟zookeeper自带的一些工具并不怎么给力。
启动服务并查看
启动服务
1
2
3
4
#进入到Zookeeper的bin目录下
cd /usr/zookeeper/zookeeper/zookeeper-3.5.4-beta/bin
#启动服务(3台都需要操作)
./zkServer.sh start
检查服务状态
1
2
3
4
5
./zkServer.sh status
---
JMX enabled by default
Using config: /usr/zookeeper/zookeeper-3.5.4-beta/bin/../conf/zoo.cfg #配置文件路径
Mode: follower #他是否为领导,leader是领导者,follower是追随者
zookeeper集群一般只有一个leader,多个follower,leader一般是相应客户端的读写请求,而follower同步数据,当leader挂掉之后就会从follower里投票选举一个leader出来。
可以用jps命令查看zookeeper的进程:
1
2
3
#执行命令jps
20348 Jps
4233 QuorumPeerMain
三、Kafka集群搭建
注:在单台机器上也可以搭建集群,配置步骤和多台服务器的将配置文件复制三份,分别配置下端口,在分开启动。
准备工作
1
2
3
4
5
6
7
8
#创建目录
cd /usr/
mkdir kafka #创建项目目录
cd kafka
mkdir kafkalogs #创建kafka消息目录,主要存放kafka消息
#解压软件
tar -zxvf kafka_2.11-1.1.0.tgz
修改配置文件
进入到config目录
1
cd /usr/kafka/kafka_2.11-1.1.0/config/
注:server.properties 这个文件即可。可以发现在目录下有很多配置文件,也有Zookeeper的配置文件,可以根据Kafka内带的Zookeeper集群来启动,但是建议使用独立的Zookeeper集群。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
connect-console-sink.properties
connect-console-source.properties
connect-distributed.properties
connect-file-sink.properties
connect-file-source.properties
connect-log4j.properties
connect-standalone.properties
consumer.properties
log4j.properties
producer.properties
server.properties
test-log4j.properties
tools-log4j.properties
zookeeper.properties
配置文件参数说明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
port=19092 #当前kafka对外提供服务的端口默认是9092
host.name=192.168.3.161 #这个参数默认是关闭的,在服务器上部署时需要开启
advertised.listeners=PLAINTEXT://106.14.178.39:9092 # 外网IP和端口,有外网时需要设置此属性
num.network.threads=3 #这个是borker进行网络处理的线程数
num.io.threads=8 #这个是borker进行I/O处理的线程数
log.dirs=/usr/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数。 如果配置多个目录,新创建的topic会把消息持久化存放到多个目录中,分区数最少的那个下面
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先会存储到缓冲区,到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请求的最大数,这个值不能超过java的堆栈大小
num.partitions=1 #默认的分区数,一个topic默认1个分区数
log.retention.hours=168 #默认消息的最大持久化时间,单位小时,168小时/7天
message.max.byte=5242880 #消息保存的最大值5M
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
replica.fetch.max.bytes=5242880 #取消息的最大直接数
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件中的,当超过这个值的时候,kafka会新起一个文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
zookeeper.connect=192.168.3.161:12181,192.168.3.162:12181,192.168.3.163:12181 #设置zookeeper的连接端口
delete.topic.enable=true #设置删除主题的方式,true直接删除.false添加删除标记
上面是参数的解释,实际的修改项如下:(其他参数可根据需要调整)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#broker.id 每台服务器的broker.id都不能相同
broker.id=01
#hostname 在服务器上必须开启设置
host.name=192.168.3.163
#log.dirs 日志路劲
log.dirs=/usr/kafka/kafkalogs/
#在log.retention.hours=168 下面新增下面三项
#消息保存的最大值5M
message.max.byte=5242880
#kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
default.replication.factor=2
#取消息的最大直接数
replica.fetch.max.bytes=5242880
#设置zookeeper的连接端口
zookeeper.connect=192.168.3.161:12181,192.168.3.162:12181,192.168.3.163:12181
#设置删除主题的方式,true直接删除.false添加删除标记
delete.topic.enable=true
启动Kafka集群
启动服务(三台都需要启动)
1
2
3
4
#进入到kafka的bin目录
cd /usr/kafka/kafka_2.11-1.1.0/bin
#使用kafka的server.properties配置文件启动
./kafka-server-start.sh -daemon ../config/server.properties
检查服务是否启动
1
2
3
4
#执行命令jps,看到如下情况,则表示已启动
20348 Jps
4233 QuorumPeerMain
18991 Kafka
创建Topic来验证是否创建成功 更多命令请看官方文档:http://kafka.apache.org/documentation.html
1
2
#创建Topic
./kafka-topics.sh --create --zookeeper 192.168.3.161:12181 --replication-factor 2 --partitions 1 --topic test
参数解释:
- replication-factor: 副本,复制两份
- partitions: 创建1个分区
- topic :主题为test
1 2 3 4
#在一台服务器上创建一个发布者 ./kafka-console-producer.sh --broker-list 192.168.3.162:9092 --topic test #在一台服务器上创建一个订阅者 ./kafka-console-consumer.sh --zookeeper localhost:12181 --topic test--from-beginning
注:在发布者那里发布消息,看看订阅者那里是否能正常收到,如能收到,测试成功,否则解决报错。
测试kafka容错能力
topic test的leader是3,现在kill掉服务器3上的kafka。
1
./kafka-server-stop.sh
在另一台服务器上查看 test:
1
2
3
4
./kafka-topics.sh --describe --zookeeper localhost:12181 --topic test
---
Topic:test PartitionCount:1 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 3,1 Isr: 1
另外一个节点1被选做了leader,节点3 不再出现在 Isr 副本列表中。
虽然最初负责读写消息的leader 宕掉了,但之前的消息还是可以消费的。
看来Kafka的容错机制是正常运行的。
接着在把服务3启动起来
1
./kafka-server-start.sh -daemon ../config/server.properties
kafka集群搭建完毕。
日志说明
默认kafka的日志是保存在/usr/kafka/kafka_2.11-1.1.0/logs目录下的,这里说几个需要注意的日志。
- server.log: kafka的运行日志。
- state-change.log: kafka用zookeeper来保存状态,所以可能会进行切换,切换的日志就保存在这。
- controller.log:kafka选择一个节点作为
controller,当发现有节点宕掉的时候,它负责在拥有分区的所有节点中选择新的leader,这使得Kafka可以批量的,高效的管理所有分区节点的主从关系。如果controller宕掉了,活着的节点中的一个会被切换为新的controller。
常用命令
查看创建的所有topic
1
2
3
./kafka-topics.sh --list --zookeeper localhost:12181
---
test
查看topic状态
1
2
3
4
./kafka-topics.sh --describe --zookeeper localhost:12181 --topic test
---
Topic:test PartitionCount:1 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
解释:
- 第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为只有一个分区所以下面就只加了一行。
- Leader:负责处理消息的读和写,leader是从所有节点中随机选择的。
- Replicas:列出了所有的副本节点,不管节点是否在服务中。
- Isr:是正在服务中的节点.
查看Zookeeper的目录情况
1
2
3
4
5
6
7
8
9
10
#使用客户端进入zk,首先进入bin目录
cd /usr/zookeeper/zookeeper/zookeeper-3.5.4-beta/bin
#默认是不用加server参数的,因为这里修改了默认的端口
./zkCli.sh -server 127.0.0.1:12181
#查看zookeeper的所有指令
[zk: 127.0.0.1:12181(CONNECTED) 0] help
#查看目录情况
k: 127.0.0.1:12181(CONNECTED) 0] ls /
删除kafka中的topic方法
1
2
3
4
5
6
7
8
9
10
#删除topic,只会删除zookeeper中的元数据,消息文件须手动删除
cd /usr/kafka/kafka_2.11-1.1.0/bin
./kafka-topics.sh --delete --zookeeper host:port --topic topicname
#消息文件手动删除 topic
#删除日志目录下的topic相关文件
cd /usr/zookeeper/zookeeper/zookeeper-3.5.4-beta/bin
./zkCli.sh -server 127.0.0.1:12181
deleteall /config/topics/topicname
deleteall /brokers/topics/topicname
四、Kafka集群监控工具
Kafka Eagle 用于监控 Kafka 集群中 Topic 被消费的情况。包含 Lag 的产生,Offset 的变动,Partition 的分布,Owner ,Topic 被创建的时间和修改的时间等信息。
下载地址:
http://download.smartloli.org/
文档页面:
https://ke.smartloli.org/2.Install/2.Installing.html
介绍博客:
https://www.cnblogs.com/smartloli/p/5829395.html
解压软件
1
2
3
cd /usr/
mkdir kafkaEagle
tar -zxvf kafka-eagle-web-1.2.3-bin.tar.gz
配置环境变量
1
2
export KE_HOME=/usr/kafkaEagle/kafka-eagle-web-1.2.3-bin
export PATH=$KE_HOME/bin:$PATH
修改配置文件
进入到conf目录
1
cd /usr/kafkaEagle/kafka-eagle-web-1.2.3-bin/conf/
修改system-config.properties文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
######################################
# multi zookeeper&kafka cluster list
######################################
#kafka.eagle.zk.cluster.alias=cluster1,cluster2
#cluster1.zk.list=tdn1:2181,tdn2:2181,tdn3:2181
#cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181
kafka.eagle.zk.cluster.alias=cluster
cluster.zk.list=192.168.3.161:12181,192.168.3.162:12181,192.168.3.163:12181
######################################
# zk client thread limit
######################################
kafka.zk.limit.size=25
######################################
# kafka eagle webui port
######################################
kafka.eagle.webui.port=8048
######################################
# kafka offset storage
######################################
kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=false
######################################
# alarm email configure
######################################
kafka.eagle.mail.enable=true
kafka.eagle.mail.sa=alert_sa
kafka.eagle.mail.username=alert_sa@163.com
kafka.eagle.mail.password=mqslimczkdqabbbg
kafka.eagle.mail.server.host=smtp.163.com
kafka.eagle.mail.server.port=25
######################################
# delete kafka topic token
######################################
kafka.eagle.topic.token=keadmin
######################################
# kafka sasl authenticate
######################################
kafka.eagle.sasl.enable=false
kafka.eagle.sasl.protocol=SASL_PLAINTEXT
kafka.eagle.sasl.mechanism=PLAIN
######################################
# kafka jdbc driver address(权限系统表,支持使用数据库)
######################################
kafka.eagle.driver=org.sqlite.JDBC
kafka.eagle.url=jdbc:sqlite:/usr/kafkaEagle/kafka-eagle-web-1.2.3-bin/db/ke.db
kafka.eagle.username=root
kafka.eagle.password=root
启动Kafka Eagle
1
2
3
4
5
6
# 进入bin目录
cd /usr/kafkaEagle/kafka-eagle-web-1.2.3-bin/bin/
# 修改权限
chmod +x ke.sh
./ke.sh start
启动成功
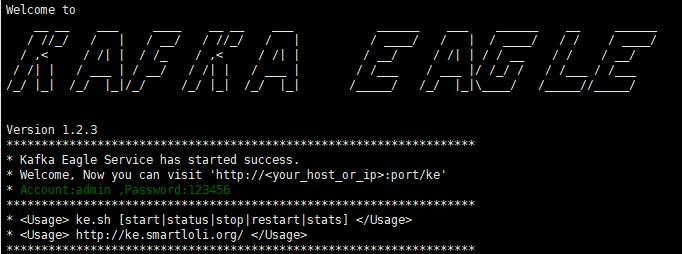 查看页面
查看页面
http://192.168.3.161:8048/ke
默认用户名/密码是admin/123456