confluent搭建文档
环境描述:
Linux:Centos7_2_64
Confluent:confluent-community-5.1.0-2.11
Kafka:kafka_2.11-1.1.0
Zookeeper:Zookeeper-3.5.4-beta
JDK:jdk1.8.0_172
一、安装confluent
-
**安装
curl和which**1
sudo yum install curl which -
安装Confluent Platform公钥,此密钥用于在YUM存储库中对包进行签名
1
sudo rpm --import https://packages.confluent.io/rpm/5.1/archive.key
-
导航到
/etc/yum.repos.d/并创建一个以confluent.repo命名的文件,添加如下内容1 2 3 4 5 6 7 8 9 10 11 12 13
[Confluent.dist] name=Confluent repository (dist) baseurl=https://packages.confluent.io/rpm/5.1/7 gpgcheck=1 gpgkey=https://packages.confluent.io/rpm/5.1/archive.key enabled=1 [Confluent] name=Confluent repository baseurl=https://packages.confluent.io/rpm/5.1 gpgcheck=1 gpgkey=https://packages.confluent.io/rpm/5.1/archive.key enabled=1
-
清除yum缓存,并安装Confluent Platform(二选一)
-
安装Confluent Platform商业版:
1
sudo yum clean all && sudo yum install confluent-platform-2.11
-
安装Confluent Platform社区版:
1
sudo yum clean all && sudo yum install confluent-community-2.11
-
-
Confluent Platform商业版将安装如下依赖,社区版只安装其中的一部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
Dependency Installed: confluent-camus.noarch 0:5.1.0-1 confluent-cli.noarch 0:5.1.0-1 confluent-common.noarch 0:5.1.0-1 confluent-control-center.noarch 0:5.1.0-1 confluent-control-center-fe.noarch 0:5.1.0-1 confluent-kafka-2.11.noarch 0:5.1.0-1 confluent-kafka-connect-elasticsearch.noarch 0:5.1.0-1 confluent-kafka-connect-hdfs.noarch 0:5.1.0-1 confluent-kafka-connect-jdbc.noarch 0:5.1.0-1 confluent-kafka-connect-jms.noarch 0:5.1.0-1 confluent-kafka-connect-replicator.noarch 0:5.1.0-1 confluent-kafka-connect-s3.noarch 0:5.1.0-1 confluent-kafka-connect-storage-common.noarch 0:5.1.0-1 confluent-kafka-rest.noarch 0:5.1.0-1 confluent-ksql.noarch 0:5.1.0-1 confluent-rebalancer.noarch 0:5.1.0-1 confluent-rest-utils.noarch 0:5.1.0-1 confluent-schema-registry.noarch 0:5.1.0-1 confluent-support-metrics.noarch 0:5.1.0-1 Complete!
二、安装ZooKeeper
Confluent Platform各个组件的配置,默认情况下,它们位于/etc/目录下。
Confluent安装包本身自带了kafka和zookeeper环境。可以使用Confluent自带环境,也可以使用单独安装的kafka和zookeeper环境,两者的配置方式相同。
本文档是在集群模式下运行ZooKeeper,集群模式至少需要三台服务器,并且必须具有奇数个服务器才能进行故障转移。
-
配置ZooKeeper
-
配置文件目录/etc/kafka/zookeeper.properties,修改如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# 每滴答的毫秒数 tickTime=2000 # 存储快照的目录 dataDir=/var/lib/zookeeper/ # 客户端端口 clientPort=2181 # 初始化系数 initLimit=5 # 同步系数 syncLimit=2 # 集群成员 server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888 # 保留在dataDir中的快照数 autopurge.snapRetainCount=3 # 清除任务时间间隔 autopurge.purgeInterval=24
-
server.* 属性的设置格式
1
server.<myid>=<hostname>:<leaderport>:<electionport>- 结构说明
myid是服务器标识号。有三台服务器,每个有不同的myid分别使用值1,2和3。hostname是服务器名称,也可以使用ip代替,推荐使用服务器名称。leaderport是领导者端口,也是通信端口。electionport是选举端口,在领导者出现故障时,进行选举时使用。
- 结构说明
-
-
创建myid文件。
-
当ZooKeeper服务器启动时,它通过引用该
myid文件来知道它是哪个服务器。例如,服务器1配置如下1
1
-
三、安装Kafka
导航到Kafka配置文件(/etc/kafka/server.properties)并自定义以下内容:
- 通过设置
zookeeper.connect属性来连接zookeeper集群。1
zookeeper.connect=zoo1:2181,zoo2:2181,zoo3:2181 - 使用以下方法之一为集群中的每个节点配置代理ID。
- 动态生成代理ID:添加
broker.id.generation.enable=true并注释掉broker.id。例如:1 2 3 4 5
############################# Server Basics ############################## # broker的ID。必须将此设置为每个代理的唯一整数。 #broker.id=0 broker.id.generation.enable=true
- 手动设置代理ID:为
broker.id每个节点设置唯一值。1 2 3 4
############################# Server Basics ############################## # broker的ID。必须将此设置为每个代理的唯一整数。 broker.id=0
- 动态生成代理ID:添加
- 配置其他代理和客户机如何使用
listeners与代理通信,以及可选的advertised.listeners。listeners:URI和侦听器名称的逗号分隔列表。1
listeners = PLAINTEXT://hostname:9092advertised.listeners:URI和侦听器名称的逗号分隔列表,供其他代理和客户机使用。该参数确保broker advertises 可从本地和外部主机访问的地址。1
advertised.listeners=PLAINTEXT://hostname:9092
四、配置Confluent
Confluent Control Center
Confluent Control Center是商业版闭源的组件,是管理和监控Kafka最全面的GUI驱动系统。
如果使用商业版,会自动下载Confluent Control Center所需要的各种依赖;如果使用社区版,需要单独下载配置。
web段页面默认的端口为9021,http://localhost:9021
- 商业版配置:
- 导航到Control Center属性文件(
/etc/confluent-control-center/control-center.properties) 并配置如下内容:1 2 3 4 5 6 7 8
# Kafka集群的主机/端口 bootstrap.servers=hostname1:port1,hostname2:port2,hostname3:port3 # 控制中心数据的位置 confluent.controlcenter.data.dir=/var/lib/confluent-control-center # the Confluent license confluent.license=<your-confluent-license> # ZooKeeper集群的主机/端口 zookeeper.connect=hostname1:port1,hostname2:port2,hostname3:port3
- 导航到Kafka服务器配置文件(
/etc/kafka/server.properties)并启用Confluent Metrics Reporter。1 2 3 4 5 6 7 8 9 10 11 12
##################### Confluent Metrics Reporter ####################### # Confluent Control Center and Confluent Auto Data Balancer integration # # Uncomment the following lines to publish monitoring data for # Confluent Control Center and Confluent Auto Data Balancer # If you are using a dedicated metrics cluster, also adjust the settings # to point to your metrics Kafka cluster. metric.reporters=io.confluent.metrics.reporter.ConfluentMetricsReporter confluent.metrics.reporter.bootstrap.servers=localhost:9092 # # Uncomment the following line if the metrics cluster has a single broker confluent.metrics.reporter.topic.replicas=1
- 将如下信息添加到Kafka Connect属性文件(
/etc/kafka/connect-distributed.properties)以添加对拦截器的支持。connect-distributed.properties为分布式的配置文件,也可以使用单机版的配置文件。1 2 3
# Interceptor setup consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor producer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor
- 单独配置: kafka版本必须在Kafka 0.10.0.0以上。
-
安装Confluent Control Center
详细步骤可参考官网:
https://docs.confluent.io/3.0.0/control-center/docs/install.html1
$ sudo yum install confluent-control-center
-
安装Confluent Metrics Clients
- 需要下载依赖包,放入到kakfa的libs目录下。
- 详细参见官网:https://docs.confluent.io/current/control-center/installation/clients.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
<repositories> <repository> <id>confluent</id> <url>http://packages.confluent.io/maven/</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.0.0-cp1</version> </dependency> <dependency> <groupId>io.confluent</groupId> <artifactId>monitoring-interceptors</artifactId> <version>4.1.0</version> </dependency> </dependencies>
-
修改配置文件
-
导航到Control Center配置文件(
/etc/confluent-control-center/control-center.properties), 并配置如下内容:1 2 3 4 5 6 7 8
# Kafka集群的主机/端口 bootstrap.servers=hostname1:port1,hostname2:port2,hostname3:port3 # 控制中心数据的位置 confluent.controlcenter.data.dir=/var/lib/confluent-control-center # the Confluent license confluent.license=<your-confluent-license> # ZooKeeper集群的主机/端口 zookeeper.connect=hostname1:port1,hostname2:port2,hostname3:port3
-
-
添加拦截器
-
将如下信息添加到Kafka Connect属性文件(
/kafka/connect-distributed.properties)1 2 3
# Interceptor setup consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor producer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor
-
-
守护线程的方式启动
1
control-center-start -daemon /etc/confluent-control-center/control-center.properties
### Schema Registry
提供Kafka数据格式的中央注册表,以保证兼容性。
Schema Registr存储所有模式的版本化历史,并允许根据配置的兼容性设置来演进模式。它还为客户端提供一个插件,用于处理以Avro格式发送的消息的模式存储和检索。
- 导航到Schema Registry配置文件(
/etc/schema-registry/schema-registry.properties) ,配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
# Schema的监听ip和port
listeners=http://0.0.0.0:8081
# 连接的zookeeper
kafkastore.connection.url=zoo1:2181,zoo2:2181,zoo3:2181
# 如果不配置该属性,将从‘kafkastore.connection.url’来获取kafka信息,默认关闭
# PLAINTEXT代表明文方式,SSL代表加密方式
kafkastore.bootstrap.servers=PLAINTEXT://localhost:9092
# 存储模式的主题的名称
kafkastore.topic=registry
# 如果为真,失败的API请求将包含额外的调试信息,包括堆栈跟踪
debug=false
详细的配置信息,参见官网:
https://docs.confluent.io/current/schema-registry/docs/config.html
常见的Schema Registry使用语法,参见官网:
https://docs.confluent.io/current/schema-registry/docs/using.html
Kafka connect
Kafka Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得能够快速定义将大量数据集合移入和移出Kafka的连接器变得简单。
Kafka Cnnect有两个核心概念:Source和Sink。 Source负责导入数据到Kafka,Sink负责从Kafka导出数据,它们都被称为Connector。
-
导航到Kafka connect配置文件(
/kafka/connect-distributed.properties),配置如下:注意:分布式的几台机器全部配置完毕,才可以使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
# 连接kafka集群 bootstrap.servers=192.168.3.161:9092,192.168.3.162:9092,192.168.3.163:9092 # 集群的惟一名称,用于形成Connect集群组。注意,这不能与使用者组id冲突 group.id=connect-cluster # 转换器指定Kafka中的数据格式以及如何将它转换成连接数据 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter # 使用json数据格式配置要成false key.converter.schemas.enable=false value.converter.schemas.enable=false # 用于offsets, config和 status data的内部转换器的配置,必须指定 internal.key.converter=org.apache.kafka.connect.json.JsonConverter internal.value.converter=org.apache.kafka.connect.json.JsonConverter # 使用json数据同样配置成false internal.key.converter.schemas.enable=false internal.value.converter.schemas.enable=false # 该主题用以保存offset信息,可以有许多分区,并且需要使用cleanup的压缩机制。(推荐partition 50,replica 3) offset.storage.topic=connect-offsets offset.storage.replication.factor=3 offset.storage.partitions=50 # 用以保存connector和task的配置信息,分区数只能是1,而且是多副本的。(推荐partition 1,replica 3) config.storage.topic=connect-configs config.storage.replication.factor=3 config.storage.partitions=1 # 用于存储状态的主题。可以有多个分区,并且需要使用cleanup的压缩机制。(推荐partition 10,replica 3) status.storage.topic=connect-status status.storage.replication.factor=3 status.storage.partitions=10 # 刷新速度 offset.flush.interval.ms=10000 # 监听的REST API的主机名和端口 #rest.host.name= #rest.port=8083 # 提供给其他工作者的主机名和端口,连接到的url。 #rest.advertised.host.name= #rest.advertised.port= # 插件及其依赖项的jar的目录 plugin.path=/usr/share/java,/usr/share/confluent-hub-components
-
创建分布式模式所必须的几个topic
1 2 3 4 5 6 7 8
# config.storage.topic=connect-configs $ bin/kafka-topics --create --zookeeper localhost:2181 --topic connect-configs --replication-factor 3 --partitions 1 --config cleanup.policy=compact # offset.storage.topic=connect-offsets $ bin/kafka-topics --create --zookeeper localhost:2181 --topic connect-offsets --replication-factor 3 --partitions 50 --config cleanup.policy=compact # status.storage.topic=connect-status $ $ bin/kafka-topics --create --zookeeper localhost:2181 --topic connect-status --replication-factor 3 --partitions 10 --config cleanup.policy=compact
- config.storage.topic:topic用于存储connector和任务配置;注意,这应该是一个单个的partition,多副本的topic
- offset.storage.topic:用于存储offsets;这个topic应该配置多个partition和副本。
- status.storage.topic:用于存储状态;这个topic 可以有多个partitions和副本
-
启动worker
1
connect-distributed.sh -daemon ../config/connect-distributed.properties-
使用restful启动connect
1 2 3 4 5 6
curl 'http://localhost:8083/connectors' -X POST -i -H "Content-Type:application/json" -d '{ "name":"名称", "config":{"属性1":"1", "属性2":"2", "属性3":"3"} }'
-
示例,启动MQTT:
1 2 3 4 5 6 7 8 9 10 11
curl 'http://localhost:8083/connectors' -X POST -i -H "Content-Type:application/json" -d '{"name": "mqtt", "config": { "tasks.max": "1", "connector.class": "io.confluent.connect.mqtt.MqttSourceConnector", "mqtt.server.uri": "tcp://192.168.3.207:1883", "mqtt.topics": "temperature", "kafka.topic": "mqtt", "confluent.topic.bootstrap.servers":"192.168.3.163:9092" } }'
-
-
查看所有connnect,以及状态
1 2 3 4
# 查看connoect curl -X GET 'http://localhost:8083/connectors' # 查看状态 curl -X GET 'http://localhost:8083/connectors/connoect名称/status'
-
配置日志
-
默认情况下日志只在控制台输出,如需要保存文件需要修改配置connect-log4j.properties,例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
log4j.rootLogger=INFO, stdout, stdfile log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c:%L)%n log4j.appender.stdfile=org.apache.log4j.DailyRollingFileAppender log4j.appender.stdfile.DatePattern='.'yyyy-MM-dd-HH log4j.appender.stdfile.File=${kafka.logs.dir}/stdout.log log4j.appender.stdfile.layout=org.apache.log4j.PatternLayout log4j.appender.stdfile.layout.ConversionPattern=[%d] %p %m (%c)%n log4j.logger.org.apache.zookeeper=ERROR log4j.logger.org.I0Itec.zkclient=ERROR log4j.logger.org.reflections=ERROR
-
Start Confluent Platform
使用systemd服务启动Confluent平台及其组件。您可以使用systemctl start命令立即启动,也可以使用systemctl enable命令自动启动。
ZooKeeper、Kafka和Schema Registry必须按照这个特定顺序启动,并且必须在其他组件之前启动。可以使用start-cp.sh脚本按顺序启动Confluent平台所有组件,使用stop-cp.sh脚本停止所有组件。
-
启动ZooKeeper
1
sudo systemctl start confluent-zookeeper -
启动Kafka
1
sudo systemctl start confluent-kafka -
启动Schema Registry
1
sudo systemctl start confluent-schema-registry -
根据需要启动其他Confluent平台组件
-
Control Center
1
sudo systemctl start confluent-control-center -
Kafka Connect
1
sudo systemctl start confluent-kafka-connect -
Kafka REST Proxy
1
sudo systemctl start confluent-kafka-rest -
KSQL
1
sudo systemctl start confluent-ksql
-
-
检查服务状态
1
systemctl status confluent*
Uninstall
运行此命令卸载Confluent平台,其中<component-name>是confluent-platform 或confluent-community的名称,需要将安装时下载的依赖全部卸载,才可以重新安装。
1
sudo yum remove <component-name>
例如:
1
sudo yum remove confluent-community-2.11
四、插件管理
Confluent Hub
Confluent Hub客户端是一个命令行工具,可以轻松地将Confluent Hub中的组件安装和更新到本地Confluent Platform中。
-
下载并解压
-
添加环境变量
1 2 3 4 5
# vim /etc/profile export CONFLUENT_HOME=/usr/confluent_hub export PATH=$CONFLUENT_HOME/bin:$PATH # source /etc/profile # which confluent-hub
-
安装命令
1
confluent-hub install <owner>/<component>:<version>
<owner>是Confluent Hub上组件所有者的名称。<component>是Confluent Hub上组件的名称。<version>是Confluent Hub上的组件版本。
MQTT安装示例
- 执行下载命令
1
confluent-hub install confluentinc/kafka-connect-mqtt:1.1.0-preview
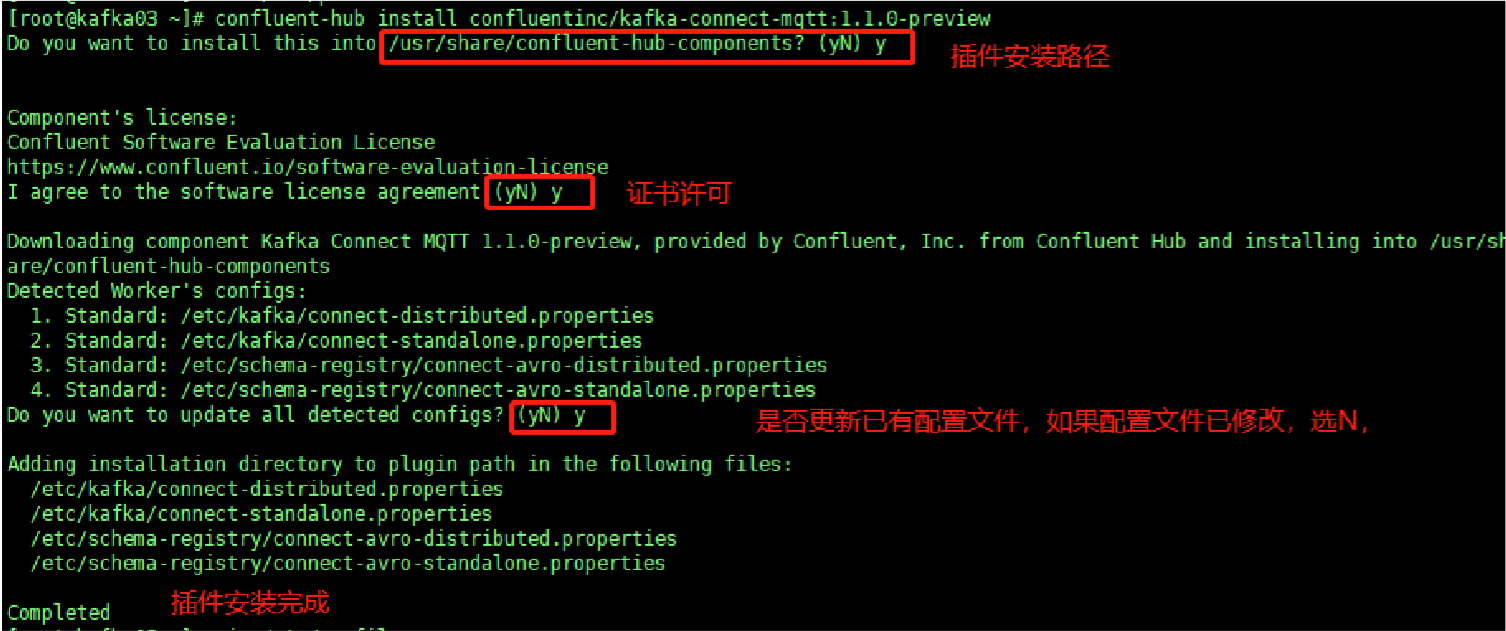
- 导航到MQTT配置文件目录
/usr/share/confluent-hub-components/confluentinc-kafka-connect-mqtt/etc/source-anonymous.properties,修改如下内容:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# # Copyright [2018 - 2018] Confluent Inc. # name=anonymous tasks.max=1 # 连接使用的java类 connector.class=io.confluent.connect.mqtt.MqttSourceConnector # 要连接的MQTT代理列表 mqtt.server.uri=tcp://127.0.0.1:32790 # 要订阅的MQTT主题 mqtt.topics=foo # 数据写入的Kafka主题 kafka.topic=mqtt # 连接的kafka confluent.topic.bootstrap.servers=192.168.3.163:9092
详细配置信息,参见官网:
- 配置worker
无论是运行独立模式还是分布式模式,都可以通过将包含必需选项的属性文件作为第一个参数传递给worker进程来配置Kafka Connect工作程序。Confluent Platform附带了一些示例配置文件。建议使用这些文件
etc/schema-registry/connect-avro-[standalone|distributed].properties作为第一个参数,因为它们包含使用Confluent Platform的Avro转换器与Schema Registry集成的必要配置。 在分布式模式下,如果每个主机运行多个worker线程,则以下设置必须为每个实例具有不同的值:rest.port- REST接口侦听HTTP请求的端口
- 启动命令
独立模式
1
connect-standalone worker.properties connector1.properties [ connector2.properties connector3.properties ... ]
分布式模式
1
connect-distributed worker.properties connector1.properties [ connector2.properties connector3.properties ... ]
示例:
1
connect-distributed -daemon /etc/schema-registry/connect-avro-distributed.properties /usr/share/confluent-hub-components/confluentinc-kafka-connect-mqtt/etc/source-anonymous.properties详细配置信息,参见官网: